M&D에서 박사놈 덕분에 아주 좁은 새장에 갇힌 상태로 아주 협소한 영역에서 백엔드 엔지니어링이란 것을 맛만 봤다. DB 테이블을 설계할 권한을 주지 않고, 코드 아키텍처도 없어서 만들려고하니 바꾸지 말라고 하고, 서비스 E2E 테스트만 시키기, 불완전한 코드를 현장에 설치 시키기 등 갖은 양아치 짓을 당했다. FastAPI 프로젝트 구조를 열심히 구글링하지 않았거나, ChatGPT가 멍청했더라면 그 당시에 깨닫지 못하여 더 깊은 심연에 있을 생각을 하니 상상만해도 어지럽다. 세상이 빠르게 발전한 덕분에 코드 베이스가 얼마나 유지보수성이 떨어지는 상태인지 알 수 있었고, 이를 바로잡을 수 있는 기회가 있었다.
Text-to-SQL이나 마이크로 서비스 및 API 제작을 위해 소프트웨어 아키텍처 설계 및 코드 베이스를 닦아놓는 일이 우선적으로 필요해서 (기반을 닦아놓는게 필요해서) 기능을 만드는 일은 하지 않았다. DB가 .csv 파일로 존재하기에 search라는 걸 빠르고 효율적으로 구축할 수가 없는 상태였다. TimescaleDB나 다른 실시간 센서 데이터를 저장할만한 DB를 갖추고 (인프라를 갖추고) 기능을 제작하는게 맞다고 판단했다. 또한 LLM 기능을 만들 수 있는 기회가 있었지만 실행에 옮기지는 않았는데, LLM 기능은 LLM을 위해 시스템을 다시 설계하거나 기존 시스템이 갖고 있는 기능들을 tool로 활용하도록 설계되어야 한다고 생각했기 때문이다.
코드 베이스를 닦으면서 회사 조직 및 대표, 팀장들의 머리에 소프트웨어 조직 OS가 없어서 설치하는 과정이 필요하다고 인지했다. 하지만 어디서부터 어떻게 구축해야할 지 모르겠고.. 자신도 없었고.. 대표가 맘에 들지 않았기에 회사를 잘되게하기 위해 힘내서 밀어 붙힐 마음도 없었다. 그래서 다른 회사에 서류를 열심히 넣고 이를 갈고 과제를 완수해 회사를 떠났다! AX, DX는 조직의 생각과 습관을 바꿔놓는 일이기때문에 달리 말하면 사람을 바꾸는 일이라 매우 고되고 호흡이 긴 작업인듯하다. 그래서 많이들 실패하고 유니콘이 잘 안나오는게 아닌가싶다. 코칭? 컨설팅?
Spiritus LAB에서 Ripples MVE 제작
연초에는 제품 출시에 대한 생각을 거의 포기한 상태로 활동했다. 캐릭터를 만들어내는 과정이 혹시 잘못된건가? 시간이 꽤 흘렀으니 새로운 연구가 나온게 있을까? 라는 생각에 논문을 뒤져봤다. 생각보다 출판된 논문들과 우리가 하고 있는 작업의 결이 매우 비슷하다는 점을 발견했다. 그리고나서 인사이트를 얻기 위해 논문 재현 작업을 해보았는데, 작업이 생각보다 길어져서 이대로는 제품 출시를 못할거 같았다. 활동한지 거의 2년이 되어가는데 결과물이 없기도하고, 혹시나 만들고자하는 아이템을 사람들이 원하지 않을 수도 있다는 생각이 계속 머릿속을 맴돌았다. 그래서 서비스 수요가 증명이 되고나서 활동을 이어나가고 싶었다.
기존에 데스크탑 웹 기반으로 디자인 해뒀던 UI/UX를 모두 갈아엎고 모바일 기반 서비스 형태로 편지를 주고 받는다는 느낌으로 다시 디자인하자고 설득했다. 오케이 사인을 받은 다음부턴 빠르게 바이브코딩해서 하나의 시나리오만 동작하는 제품을 만들었고, 모두연 슬랙과 랩원 지인들을 통해 가설 검증을 진행했다. 사용 중 눈물을 흘렸다는 후기를 듣고 아이템에 약간의 확신이 생겨서 조금 더 제품스럽게 만들기로 한 상태다. 지금은 로그인도 없고 캐릭터들에게 편지를 받으면 사용 후기를 남기는 닫힌 구조로 설계되어있다.
인바디 수치 D로 만들자
작년 계획
[ ] 근육량, 체지방량 숫자 상관없이 그냥 D만 나오면 상관없음
세부 목표 회고
헬스 자체를 딱 1년 중 1달만 했다. 한 이유도 허리와 목이 너무 아파서였는데, 통증 원인이 베개와 매트리스임을 발견하고 개선했더니 괜찮아져서 운동을 안가게됐다. 또한, 헬스보다 다른 일이 더 재밌다보니 계속 우선순위에서 밀렸다. 헬스장은 멀어서 안가니까 집에서 할 수 있는 걸 찾아야겠다. 기능성 운동 위주로 전신을 잘 사용하는 홈트로다가. 인바디 수치를 목표로 잡기보다는 맨몸 플로우 운동 자세를 수행해내는걸로 계획을 수정해야겠다.
2025 한 일 되돌아보기
상반기
AX/DX + 제품 개발 = 아직 못하겠다
소프트웨어 조직 운영 체계가 없는 곳에서 제품 개발하기란 사내 조직도 개편하면서 제품을 개발해야되는 일이여서 그 당시 나한테는 도전적인 일이었다. 소프트웨어 조직을 경험해본적이 없었고, 소프트웨어 제품 개발에 전문성도 없었기에 양쪽 다 충족시키며 일하는게 쉽지 않았다. 나한테 두 능력이 필요하긴하지만 엠앤디에서는 두 실력을 갈고닦기엔 어려운 환경인거 같았고, 두 조건 중 하나가 충족된 환경으로 가서 나머지 하나의 전문성을 기를 수 있는 곳으로의 이직이 괜찮은 전략같았다.
이직 성공!
이직을 위해 이력서나 포트폴리오 만드는데 엠앤디에서의 서류 검토 및 면접관 경험이 아주 도움 되었다. 서류를 볼 때 어디를 먼저 보는지, 면접관으로서 어떤 부분이 궁금한지를 알게되었다. 그런 관점에서 내 서류를 보니 수정 방향이 딱 잡혔다. 하지만 그렇다고 서류를 많이 붙지도 않았다. 2-3곳인가 붙었었다. 백엔드로 직무 전환해서 이직하려다보니 경력이 없던게 크지 않았을까 싶다. 운이 좋게도 현재 회사에 서류를 통과하고 과제를 이악물고 수행해서 채용 절차가 진행됐다. 그리고 감사하게도 지금 팀장님이 강하게 내가 필요하다고 어필해줘서 합격하고 현재 만족스럽게 일을 하는 중이다.
결혼식 없는 결혼
결혼식 없는 결혼을 어찌저찌 잘 끝낸듯하다! 결혼식이 없다보니 맺고 끊음이 정확하게 없다. 그래서 끝내었다는 느낌도 정확하게 들지 않는다. 결혼을 하기위해서는 (웨딩링 구매, 프로포즈, 스드메, 웨딩 촬영장, 상견례, 웨딩밴드 구매, 결혼식장, 청첩장, 신혼집)을 위한 선택 사항들이 있다. 이 중 (결혼식장, 청첩장, 신혼집)은 빠진 상태로 일정이 진행되었다. (웨딩링, 프로포즈)는 내가 말아먹어버렸다. 웨딩 촬영 전에 반지를 구매해야된다는 사실을 몰라서.. 반지 제작에 2-3달이 걸리는지도 몰라서.. 일정이 꼬여버리는 바람에 망했다. 연초에 제주도 (스드메, 웨딩 촬영장)을 찾고 5월로 예약을 했다. 이후 상견례는 협의해서 6월로 날짜 맞췄었다. 상견례 이후 7월 초부터 같이 살고 있다.
하반기
온라인 웨딩 웹 제작
결혼식은 안해도 사람들에게 잘 살겠다고 선언하는 무언가는 있으면 좋겠다고 생각했다. 그래서 웹사이트를 만들었고, 처음 기획에 비해 엄청 간소화된 버전으로 제작했다. 만들면서 내가 기획을 대충 크게크게 하다보니 디자이너인 와이프가 좀 화가 많이 났었다. 기획 디테일하게 하는게 쉽지않네; 둘 다 연말 다가오니 지쳐서 최소한만 만족시키자가 되어 완성을 하게 됐다.
버즈니 Viskit
LLM을 이용하여 프로덕트를 만들고 싶었는데 버즈니에 딱 합격해서 따악 원하는 일을 하고 있다. 고등학교때나 대학교때 얼른 사회의 흐름을 타면서 내가 사회에 영향을 끼치고 싶었는데 그 시기가 지금 온 듯하다. 어릴때는 구경만 할수밖에 없었고, 내가 하고 싶다고 할 수 없었다. 내가 회사 차리기엔 두려웠고 남의 회사에서 일하기엔 전문성이 없었다. 진짜 뭔가 염원했던 일을 하고 있다는 기분이라 행복하다. B2C 서비스를 성장시키는 방법이나, AI 제품을 만드는 경험을 모조리 학습해서 계속해서 재밌는 일을 이어하고 싶다.
회사에서 매달 AI 툴 사용비로 $100 지원해줬다. ChatGPT Plus, Claude Pro, Cursor Pro를 사용했었는데, 최근 $150까지 올려줘서 Cluade Max 구독으로 바꿨다. Agentic coding을 해볼 수 있는 기회를 제공받아서 너무 감사하고, 회사 환경도 장려하는 분위기라 자유롭게 써보기 좋았다. 현재까지 사용하면서 느낀 점은 "맥락만 충분히 주면 알아서 잘 해준다"이다. 그렇다면 어떻게 올바른 맥락을 제공해줄 수 있는지가 관건인데, 내 머릿속에 있는 맥락과 자료로써 존재하는 맥락을 내가 알아차리고 잘 설명해주는 일이 필요하다. skill이나 tool은 이러한 목적에서 아직 그렇게 유용한지는 모르겠어서 사용하지 않고 있다. plan 모드를 켜서 내가 맥락을 충분히 줬는지 검토하고 이제는 됐다싶으면 코드 작성을 시키는 편이다.
일하는 방식도 예전과는 달라진듯하다. 백엔드 코드를 터미널에서만 테스트 해봤다면 이제는 프론트엔드 코드를 작성하는데 어려움이 없어졌기에 직접 화면을 그리고 작성된 백엔드 API를 연결해서 end-to-end 테스트를 해볼 수 있어졌다. 그러면서 UX, 상품성을 고려할 수 있게되고 어떤 기능이 최소한으로 필요한지 어떤 코드가 진짜로 필요한지 고민할 수 있게 된 점이 즐겁다.
총평
제조 조직 AX, DX를 하면서 동시에 제품 개발도 하는건 쉽지않다.
관습을 벗어나는 길을 가는 데에 한국에선 많은 설명이 필요하다.
드디어 B2C, AI 제품을 만드는 일을 한다!
2026 목표와 할 일
이사 잘 하자
잔금 대출: 5월?
가구 및 가전 구매: 3월, 4월?
현재 집 전세대출 연장: 1월에 집주인 얘기, 3월에 실행
신혼여행 무사히 갔다오자
일정 짜기: 1월
항공권 예약: 이미 완료
숙소 및 호주 국내선 예약: 1월
혼인신고: 8월? 9월?
LLM Product로 돈 벌자
버즈니 - Viskit 내가 만든 기능이 유료 전환을 일으키면 좋겠다 (기획-개발-매출로 이어지는 과정을 내가 모두 겪어보는게 목표다)
모두연 SpiritusLAB - Ripples DAU 10명 달성하기, 사람들이 제공하려는 가치를 느끼고 있는지 판단할 수 있는 지표 및 기능 만들기
최근 성공적으로 이직하여 새로운 출발을 앞두고 있다. 지난 회사에서 보낸 시간으로 여러모로 값진 성장을 할 수 있었다. 특히 백엔드 엔지니어로서, 그리고 한 명의 팀원으로서 겪었던 어려움과 이를 통해 얻은 배움을 잊기 전에 기록하며 스스로를 다잡아보려 한다.
하드 스킬 관점
작년 7월, 백엔드 직무로 전환한 이후 마이크로 서비스 개발부터 시작해 점차 서비스 전체의 구조를 이해하고 개선하는 역량을 기를 수 있었다. 알고리즘 연구원으로 쌓았던 도메인 지식에 더해, ChatGPT, Claude, Gemini와 같은 AI 도구들을 적극적으로 활용하여 코드를 작성하고 리뷰하여 단기간에 압축적인 성장을 경험했다. 막연했던 개념들이 실제 제품 개발 과정에서 어떻게 작동하는지 체득하는 할 수 있는 시간이었다.
기술적 성장을 이끈 두 가지 키워드
1. 테스트 코드의 부재가 알려준 것들
이전까지는 테스트 코드가 '있으면 좋은 것' 정도로 막연하게 생각했다. 하지만 테스트 코드가 없는 환경을 직접 경험하며, 그것이 단순히 좋은 습관을 넘어 '제품의 안정성과 팀의 생산성을 지키는 핵심 요소'임을 절절히 깨달았다.
예측 불가능한 사이드 이펙트: 새로운 기능을 추가하거나 기존 로직을 수정했을 때, 어떤 기능에 예상치 못한 영향을 미칠지 파악하기 어려웠다. 이로 인해 변경에 대한 확신이 부족해지고, 잠재적인 불안감을 안고 개발을 진행해야 했다.
불필요한 커뮤니케이션 비용: 기능 장애가 프론트엔드단에서 먼저 발견되어 백엔드팀에 전달되는 일이 잦았다. 이는 결국 팀 전체의 리소스를 불필요한 소통에 소모하게 만드는 결과를 낳았다.
심리적 장벽: 시스템에 대한 히스토리를 모르는 새로운 동료가 합류했을 때, 코드 수정이 가져올 파급 효과를 알기 어려워 적극적으로 기여하기 힘든 심리적 장벽이 생길 수 있다는 점을 알게 되었다. (새로운 동료가 나였다.)
2. 견고한 아키텍처의 필요성
과거에는 MVC와 같은 디자인 패턴이 때로 불필요하게 코드를 복잡하게 만든다고 생각한 적도 있었다. 하지만 역할과 책임이 분리되지 않은 아키텍처가 장기적으로 어떤 문제를 만들어내는지 직접 겪으며 생각이 완전히 바뀌었다.
로직이 특정 계층에 집중되고 관심사가 분리되지 않으면, 코드의 재사용성이 떨어지고 중복 코드가 늘어난다는 점을 목격할 수 있었다. 무엇보다 큰 문제는 테스트하기 어려운 구조가 된다는 점이었다. 각 로직을 독립적으로 테스트할 수 없고 항상 전체 API를 호출해서만 검증할 수 있다면, 쉽사리 테스트 코드를 작성할 마음이 안생기고 기존에 있던 코드에 테스트 코드를 작성하기도 쉽지 않았다. [1]
결국 테스트 코드와 견고한 아키텍처의 부재는 서로 맞물려 개발 생산성을 저하시키고, 협업의 어려움을 가중시킨다는 사실을 체감했다. 이러한 경험을 바탕으로 연초에 리팩토링을 건의하고 아키텍처 설계를 고민해볼 수 있었던 것은 엔지니어로서 큰 자산이 되었다. (실제 리팩토링은 기존에 코드를 작성하던 개발자가 담당했다.)
소프트 스킬과 조직에 대한 관점
이전 직장은 IT 분야와는 다른 산업적 배경을 가진 조직이었다. 덕분에 일반적인 IT 스타트업과는 다른 환경 속에서 조직 문화를 경험하고 소프트 스킬의 중요성을 다시 한번 절감할 수 있었다.
심리적 안정감의 가치: 팀원들이 결과에 대한 두려움 없이 문제를 제기하고 솔직한 의견을 나눌 수 있는 '심리적 안정감'이 왜 중요한지 깨달았다. 심리적 안정감이 부족한 환경에서는 고객의 가치보다 내부의 복잡한 역학 관계에 더 집중하게 되고, 문제 해결보다는 책임 회피에 에너지를 쓰게 될 수 있다는 것을 보았다.
불안감 관리 능력 체득: 개인적으로는 높은 심리적 압박감을 느끼는 시기도 있었다. 하지만 이 과정을 통해 불안감이 극심해질 때 제 몸과 마음이 어떻게 반응하는지 명확히 알게 되었다. 그리고 어떻게 해야 스스로를 돌보고 다시 나아갈 힘을 얻을 수 있는지, 나만의 회복 방법을 터득하는 계기가 되었다.
마치며
결코 쉽지만은 않은 시간이었지만, 돌이켜보면 그 어떤 환경보다 값진 배움을 얻었던 시간이었다. 기술의 중요성은 물론, 함께 일하는 사람들과 건강한 문화를 만드는 것이 얼마나 중요한지를 온몸으로 배웠다. 이 소중한 경험들을 자양분 삼아, 앞으로 새로운 환경에서는 함께 일하고 싶은 사람이자 엔지니어로 기여하고 싶다.
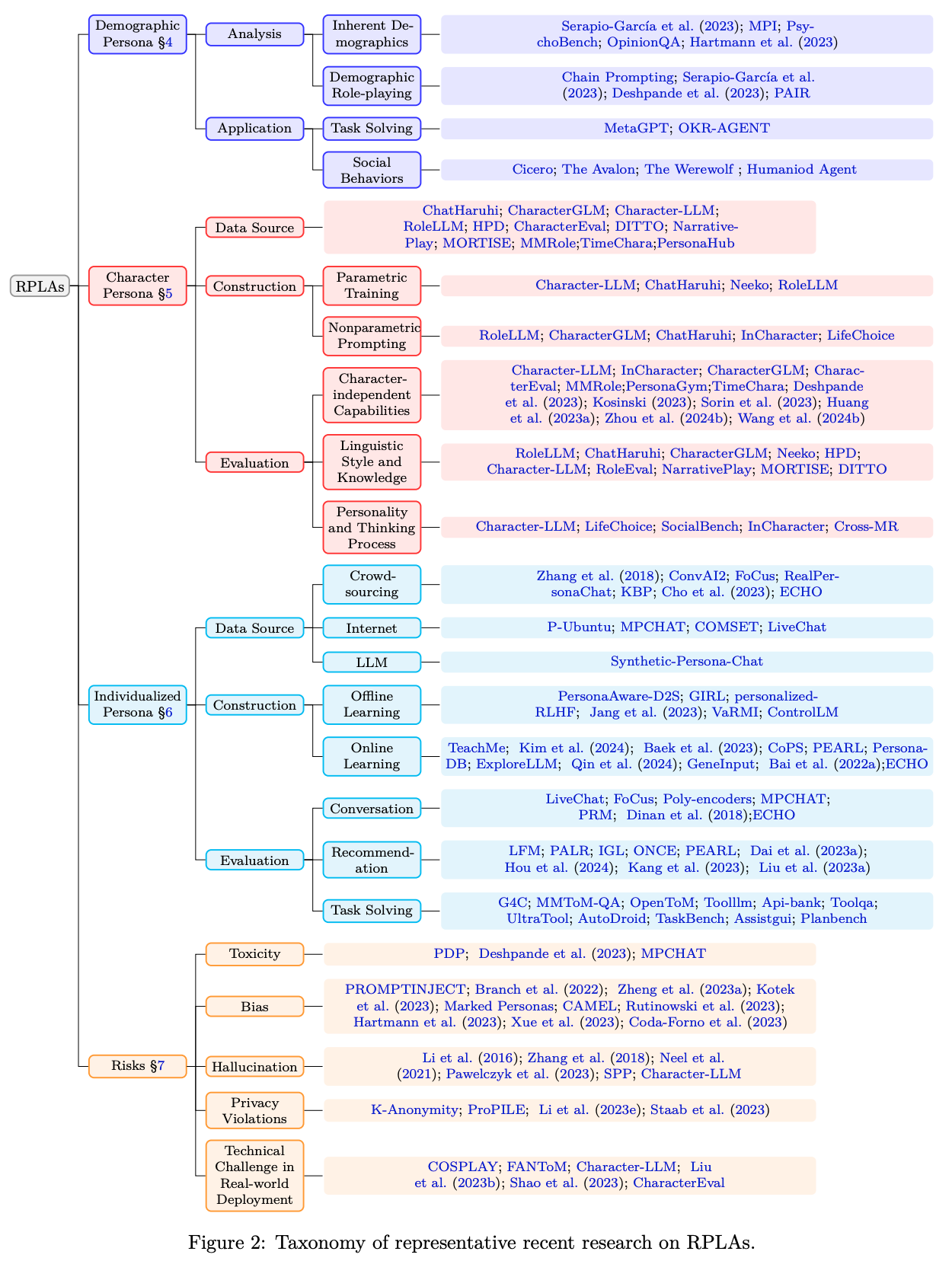
GPT가 요약을 생성하고, 사람이 검토한 내용입니다. 어떤 단락에 어떤 내용이 있는지 빠르게 파악하고, 해당 단락에서 소개되는 논문을 찾는데에 도움이 되고자 정리했습니다.
1. Introduction
최근 대형 언어 모델(LLM)의 비약적인 발전과 함께, **역할 놀이 언어 에이전트(RPLA)**가 주목받고 있습니다. 이들 에이전트는 주어진 페르소나를 기반으로 역사적 인물, 소설 속 캐릭터, 또는 개인의 특성을 생생하게 재현함으로써 감성 동반자, 게임 캐릭터, 개인 비서 등 다양한 응용 분야에 활용되고 있습니다. 이번 포스팅에서는 논문의 전체 구조와 세부 내용—페르소나의 분류, 구축 방법론, 평가 체계, 그리고 잠재적 위험 요소와 향후 연구 방향—을 자세히 살펴보겠습니다.
배경 및 발전 동향: LLM의 최신 연구 동향과 그로 인한 RPLA의 발전 과정을 설명합니다.
RPLA의 개념과 정의: 역할 놀이 언어 에이전트의 기본 개념, 그리고 이를 구성하는 핵심 요소들을 제시합니다.
페르소나 분류 체계:
Demographic Persona: 집단의 통계적 특성과 고정된 사회적 역할(예: 직업, 성별, 성격 유형)을 반영.
Character Persona: 역사적 인물이나 소설, 영화 속 잘 알려진 캐릭터의 구체적인 특성을 재현.
Individualized Persona: 사용자의 개인 데이터를 기반으로 지속적으로 갱신되는 맞춤형 프로필.
구축 방법론:
Parametric Training: 대규모 사전 학습, 지도학습, 강화학습을 통해 페르소나의 내재적 지식을 주입.
Nonparametric Prompting: 프롬프트 기반 인-컨텍스트 러닝을 활용하여, 별도의 재학습 없이도 페르소나를 즉각적으로 구현.
평가 체계: 역할 수행 능력(대화 몰입도, 유창성 등)과 페르소나 충실도(언어 스타일, 지식, 성격 재현 등)를 다양한 자동 및 인간 평가 기법으로 검증.
위험 요소 및 한계: 편향, 독성(토xic) 문제, 할루시네이션 등 RPLA 개발에 따른 부정적 측면과 이를 완화하기 위한 연구 방향.
미래 연구 방향: 안전하고 윤리적인 AI 동반자 구현, 개인화의 지속적 진화, 다중 모달 데이터 통합 등 앞으로의 도전 과제와 발전 가능성.
2. Preliminary
2.1 The Roadmap of Large Language Models
최근 LLM은 인-컨텍스트 러닝, 인스트럭션 팔로잉, 단계별 추론 등 다양한 인간 유사 능력을 보여주며, 그 결과로 역할 놀이와 같은 복잡한 사회적 상호작용을 재현할 수 있게 되었습니다.
Emerged Abilities in LLMs: LLM에서 새롭게 등장한 핵심 능력들을 상세히 설명합니다. 인-컨텍스트 러닝, 인스트럭션 팔로잉, 단계별 추론 및 사회적 지능과 같은 기능들이 LLM이 복잡한 역할 놀이를 수행할 수 있도록 하는 기반임을 강조합니다.
Anthropomorphic Cognition in LLMs: LLM이 점차 인간과 유사한 인지 및 감정적 특성을 나타내기 시작했음을 논의합니다. 초기에는 의식의 출현 논의가 있었으나, 현재는 자각, 가치, 감정 인식, 심리적 특성 등 다양한 인간적 요소를 모방하는 능력이 강조됩니다. 단, 이는 실제 의식의 증거가 아니라 역할 놀이 성격의 결과임을 언급합니다.
Retrieval-augmented Generation of LLMs: 외부 정보 검색을 통합하는 Retrieval-augmented Generation(RAG) 기법을 소개합니다. RAG는 생성 과정 중 실시간으로 외부 데이터를 참조하여 사실 오류를 줄이고, 긴 컨텍스트를 처리할 수 있게 하여 역할 놀이 시나리오에서 유용함을 설명합니다.
2.2 LLM-powed Language Agnets
전통적인 심볼릭 에이전트와 강화학습 기반 에이전트의 한계를 언급하며, 최근 LLM 기반 언어 에이전트가 인간 수준의 지능과 상호작용 능력을 바탕으로 등장하고 있음을 소개합니다.
Planning Module: 실제 상황에서 에이전트가 복잡한 작업을 해결하기 위해 장기 계획을 수립하는 방법을 설명합니다. LLM 에이전트는 Chain-of-Thought나 ReAct 같은 전략을 사용해 작업을 세분화하고 환경 피드백에 따라 동적으로 계획을 조정합니다.
Tool-usage Module: LLM이 특정 전문 영역에서 발생할 수 있는 지식의 한계나 할루시네이션 문제를 보완하기 위해, 외부 API, 지식 베이스 등 외부 도구를 활용하여 보다 정확하고 맥락에 적합한 응답을 생성할 수 있음을 설명합니다.
Memory Mechanism: 에이전트가 사용자 및 환경 정보를 저장하여 지속적인 대화 맥락을 유지하는 메모리 메커니즘의 중요성을 다룹니다. 단기 메모리(트랜스포머의 컨텍스트 한계 내 정보)와 장기 메모리(외부 저장소)를 구분하여, 개인화된 응답과 연속적인 상호작용을 가능하게 하는 역할을 설명합니다.
3. Overview of RPLAs
3.1 RPLA Definition
RPLA를 구성하는 핵심 페르소나를 세 가지로 구분하는 전체적인 틀을 제시합니다. 즉, 페르소나는 범위가 넓은 집단 특성을 반영하는 Demographic Persona, 잘 확립된 인물이나 캐릭터를 나타내는 Character Persona, 그리고 사용자 개개인의 행동과 선호를 반영하여 지속적으로 갱신되는 Individualized Persona로 분류됩니다.
(1) Demographic Persona
Demographic Persona는 직업, 성별, 인종, 성격 등과 같이 통계적 또는 집단적 특성을 반영하는 페르소나입니다. 이들은 LLM이 사전 학습 데이터에 내재한 통계적 패턴을 활용해 간단한 프롬프트(예: “당신은 수학자입니다”)로 쉽게 활성화되며, 특정 집단의 전형적인 행동과 언어 패턴을 시뮬레이션하는 데 효과적입니다.
(2) Character Persona
Character Persona는 역사적 인물, 소설, 영화 등에서 잘 알려진 인물이나 캐릭터의 고유 특성을 재현하는 데 중점을 둡니다. 이 페르소나는 전기, 소설, 영화 스크립트 등 다양한 자료로부터 데이터를 수집하여, 해당 인물의 배경, 성격, 언어 스타일 및 내러티브를 충실하게 반영하는 역할을 수행합니다. 주로 엔터테인먼트나 감성적 몰입을 위한 응용에 사용됩니다.
(3) Individualized Persona
Individualized Persona는 개별 사용자의 대화, 행동, 선호도 등에서 추출된 데이터를 기반으로 구축됩니다. 이러한 페르소나는 사용자의 지속적인 상호작용을 통해 변화하며, 개인화된 서비스(예: 개인 비서, 디지털 클론)를 제공하기 위해 사용됩니다. 데이터가 지속적으로 갱신됨에 따라 에이전트의 응답도 동적으로 변화하게 됩니다.
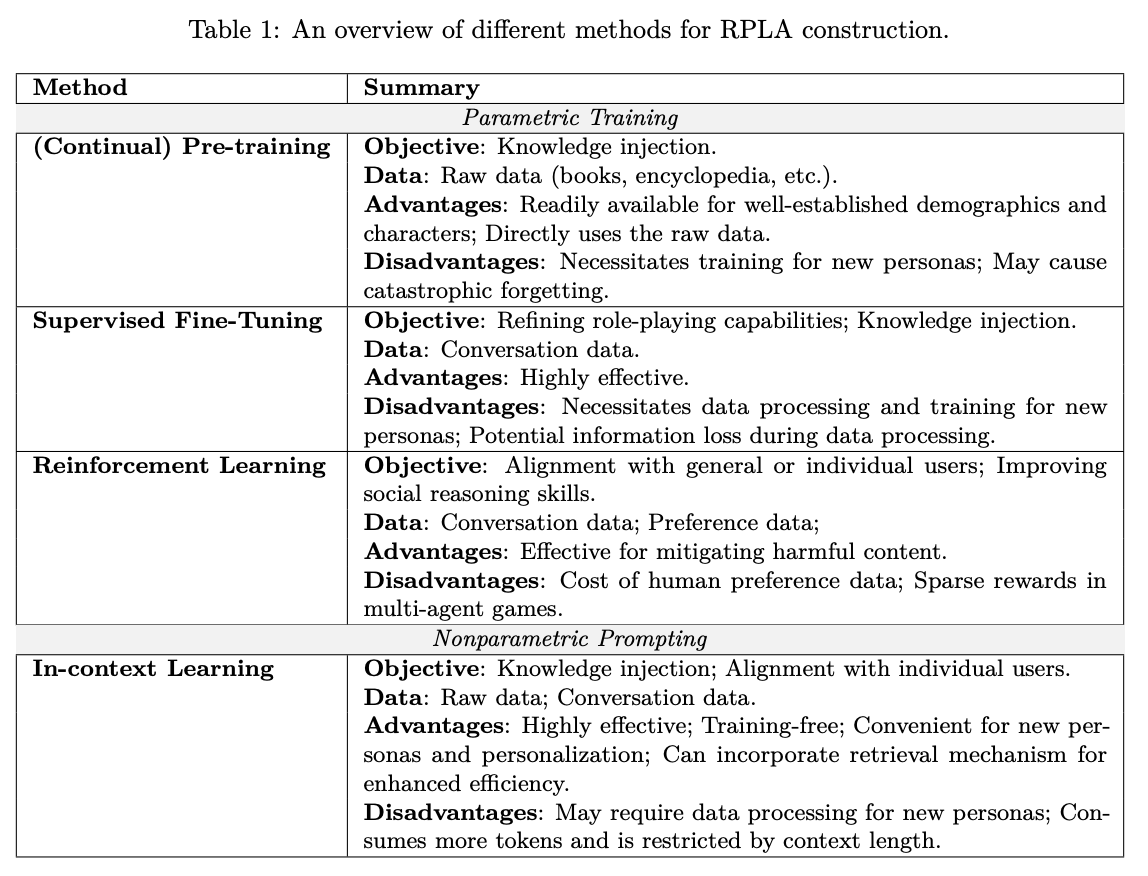
3.2 RPLA Construction
RPLA가 어떻게 복잡한 페르소나를 시뮬레이션하기 위해 다양한 데이터(설명적 서술, 대화, 역사적 행동, 문학 등)를 활용하여 구축되는지 개괄합니다. 즉, RPLA는 다양한 자료로부터 얻은 페르소나 데이터를 기반으로 에이전트의 역할과 행동을 구성합니다.
Parametric Training 접근법
Parametric Training은 RPLA 구축을 위한 주요 방법 중 하나로, 사전 학습(pre-training), 지도 학습(Supervised Fine-Tuning), 그리고 강화 학습(Reinforcement Learning)을 포함합니다.
사전 학습: 대규모 원시 텍스트(예: 문학 작품, 백과사전 등)를 통해 모델이 폭넓은 페르소나 관련 지식을 내재화합니다.
지도 학습: 역할 놀이 데이터셋을 활용하여, 특정 페르소나의 특성을 더욱 세밀하게 반영하도록 모델을 미세 조정합니다.
강화 학습: 사용자 피드백이나 선호 데이터를 기반으로, 모델이 일반 사용자와의 상호작용에서 윤리적이고 사회적으로 적절한 응답을 생성할 수 있도록 추가적으로 최적화합니다.
Nonparametric Prompting 접근법
Nonparametric Prompting은 별도의 재학습 없이도 프롬프트 내에서 페르소나 정보를 제공하여 모델이 즉각적으로 역할을 수행하도록 하는 기법입니다.
프롬프트 구성 요소: 페르소나의 설명(프로필)과 함께 해당 역할에 맞는 대화 예시(데모)를 포함하여 모델에 전달합니다.
데이터 제작 방법: 온라인 리소스(예: Wikipedia, Fandom), 자동 추출(LLM으로 책이나 스크립트에서 추출), 대화 합성(역할을 학습한 LLM을 이용한 대화 데이터 생성), 그리고 인간 주석(사람이 직접 페르소나 설명, 대화 예시 제작) 등의 방법을 통해 페르소나 데이터를 생성하고 정제합니다.
기타 보완 기법: 컨텍스트 한계를 극복하기 위해 메모리 모듈을 도입하여, 모델이 필요할 때 방대한 페르소나 정보를 외부 저장소에서 동적으로 불러올 수 있도록 합니다.
3.3 RPLA Evaluation
RPLA의 평가 기준은 크게 두 축으로 구분됩니다. 하나는 전체적인 역할 수행 능력(예: 대화 몰입도, 유창성, 사회적 상호작용 등)이며, 다른 하나는 특정 페르소나를 얼마나 충실하게 재현하는지(언어 스타일, 배경 지식, 성격 및 사고 과정 등)를 평가하는 것입니다.
역할 수행 능력 평가
에이전트의 역할 수행 능력은 주로 기본 모델의 능력과 구축된 프레임워크에 기반하여 평가됩니다. 여기에는 LLM의 인류 모방 능력, 대화 참여도, 몰입감, 감정 이해, 문제 해결 능력 등 세부 지표들이 포함됩니다. 이 평가 방식은 RPLA가 사용자의 기대에 부합하는 “인간 같은” 대화를 얼마나 잘 제공하는지를 측정합니다.
페르소나 충실도 평가
페르소나 충실도는 각 RPLA가 의도된 캐릭터의 특성(지식, 언어 습관, 성격, 신념, 결정 과정 등)을 얼마나 정확하게 재현하는지를 평가합니다. 이 과정에서는 모델이 제공해야 하는 핵심 정보와 표현 방식이 올바르게 반영되는지를 중점적으로 살펴봅니다.
평가 방법론
평가에는 주로 네 가지 방법이 사용됩니다.
자동 평가(ground truth 기반): 정답과의 유사도 측정을 통해 객관적 성능 점수를 산출.
자동 평가(ground truth 없이): LLM을 평가자로 활용하거나 정해진 기준으로 모델의 응답을 분류.
다지선다형 평가: 미리 설정된 옵션 중 올바른 응답 선택 여부를 평가.
인간 평가: 전문가 또는 관련 분야 평가자가 직접 응답의 질과 페르소나 충실도를 검토.
현재 RPLA는 점차 개선되고 있으나, 여전히 완전히 인간 수준의 역할 재현에는 미치지 못하며, 특히 페르소나 충실도 측면에서는 보다 세밀한 평가 방법이 요구됩니다.
4. Demographic Persona
4.1 Definition
RPLA에 할당된 Demographic Persona는 특정 집단의 전형적인 특성—예를 들어, 직업(수학자), 취미(야구광), 성격(ENFJ) 등—을 반영하도록 설계됩니다. 이 문단은 이러한 페르소나가 해당 집단의 언어 스타일, 전문 지식, 행동 양식을 통합하여 재현된다는 점을 강조합니다.
4.2 Analysis of Demographics
RPLA는 인간과 유사한 내재적 특성(성격, 정치적 신념, 윤리적 고려 등)을 반영합니다. 이들은 지정된 페르소나에 따라 행동을 변화시킬 수 있으나, 동시에 부적절하거나 독성이 있는 응답을 유발할 위험도 내포합니다.
Inherent Demographics
RPLA가 사전 학습 데이터에 내재한 패턴 덕분에 특정 인구 통계적 특성을 자연스럽게 반영할 수 있음을 설명합니다. 이 과정에서 인간의 편향과 행동 양상이 텍스트 출력에 영향을 미쳐, 특정 집단의 특성이 과도하게 드러날 수 있음을 지적합니다.
Demographic Role-Playing
Demographic Role-Playing은 명시적으로 페르소나를 지시하는 프롬프트를 통해 모델이 특정 인구 통계적 역할을 수행하도록 유도하는 접근법입니다. 예를 들어, “당신은 활발하고 사교적인 사람입니다”와 같은 프롬프트는 에이전트가 해당 역할에 맞는 언어 스타일과 행동을 모방하도록 합니다.
4.3 Application of Demographics
특정 인구 통계적 페르소나를 할당하면, LLM이 단독 또는 다중 에이전트 시스템에서 다운스트림 작업 수행 시 성능이 향상됨을 설명합니다. 이는 전문 지식이 요구되는 작업이나 협업 상황에서 큰 도움이 됩니다.
Improving Task Solving in Single-Agent Systems
단일 에이전트에 특정 Demographic Persona를 할당하면, 해당 분야의 전문 지식이 강화되어 응답의 깊이와 질이 향상됩니다. 특히, 사전 훈련 없이도 복잡한 제로샷 문제 해결 등에서 더 통찰력 있는 답변을 제공할 수 있게 됩니다.
Improving Task Solving in Multi-Agent Systems
다중 에이전트 환경에서 다양한 인구 통계적 페르소나를 적용하면, 각 에이전트가 서로 다른 역할을 맡아 협력적 문제 해결 및 소프트웨어 개발 같은 복잡한 작업의 효율을 높일 수 있습니다. 실제 사례로 ChatDev와 MetaGPT와 같은 시스템이 소개됩니다.
Simulating Collective Social Behaviors in Multi-Agent Systems
RPLA는 전략 게임이나 사회 추리 게임 등에서 인간과 유사한 복잡한 상호작용을 시뮬레이션할 수 있습니다. 이러한 환경에서는 에이전트들이 공정함 또는 이기적인 행동을 통해 집단적 이익에 기여하거나, 외교 및 전쟁 시뮬레이션에서 뛰어난 성능을 보이는 등, 다양한 사회적 행동 패턴을 재현할 수 있음을 보여줍니다.
5. Character Persona
5.1 Definition
Character Persona 개념 소개
Character Persona는 대중에게 널리 알려진 역사적 인물, 소설·영화 캐릭터 등 구체적이고 확립된 인물의 특성을 재현하는 것을 목표로 합니다. 여기에는 기존에 잘 알려진 캐릭터뿐 아니라, 개별 사용자가 창작한 원본 캐릭터도 포함됩니다. 이러한 페르소나는 최근 Character.ai와 같이 관련 분야에서 급부상하며, LLM의 역할 놀이 응용에서 중요한 연구 주제로 자리잡고 있습니다.
효과적인 역할 놀이를 위한 필수 요건
효과적인 캐릭터 역할 재현을 위해 LLM이 해당 캐릭터의 특성을 이해하는 능력이 필수적입니다. 초기 연구에서는 ‘Character Prediction’과 ‘Personality Understanding’이라는 두 가지 측면을 통해, 모델이 텍스트에서 캐릭터의 정체, 관계, 그리고 성격적 특성을 인식하고, 미래 행동을 예측할 수 있는지에 대해 탐구하였습니다.
최근 연구 사례
캐릭터의 어투, 지식, 성격, 의사 결정에 대한 재현과 관련된 연구들이 진행되고 있습니다.
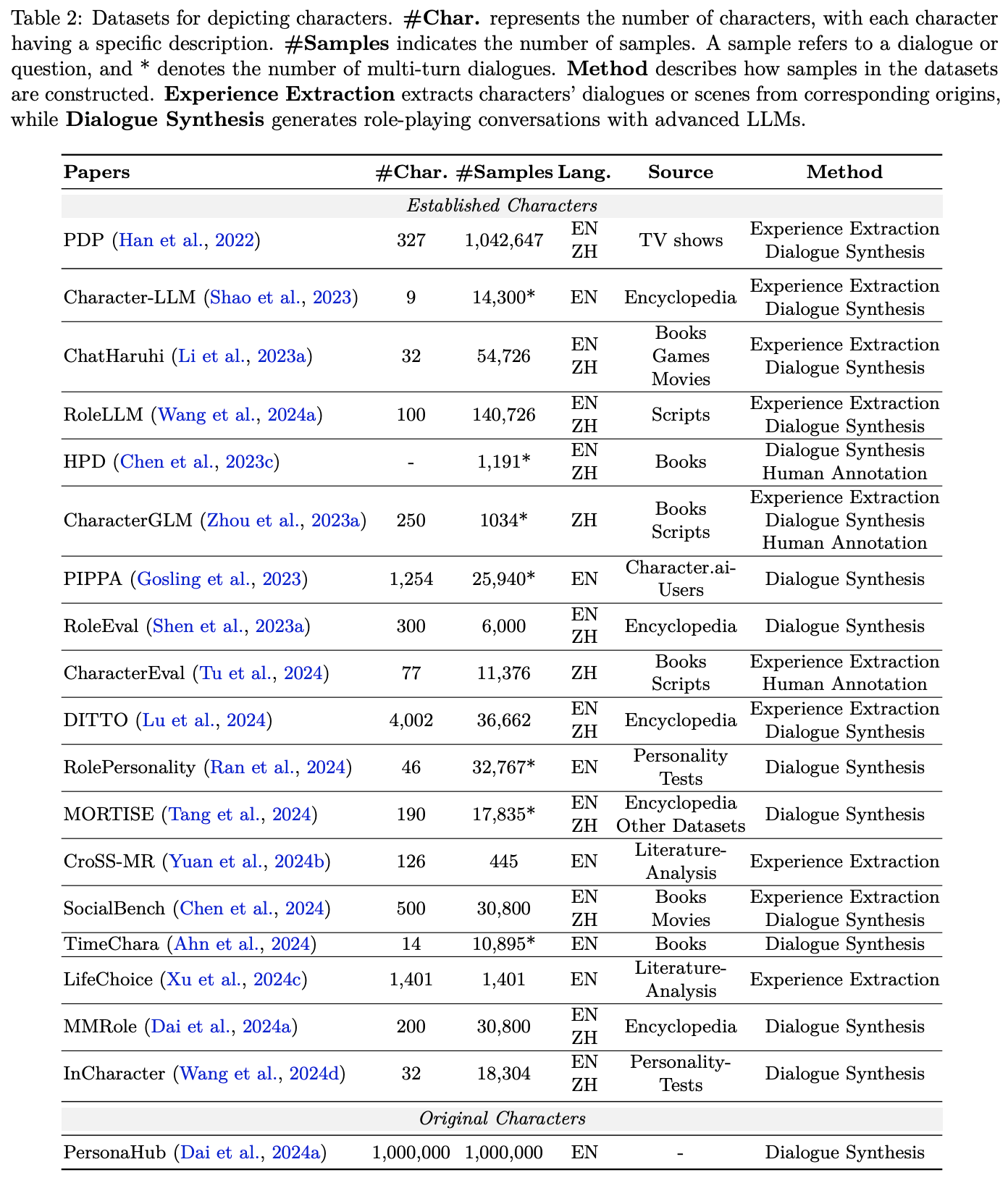
5.2 Data for Character RPLAs
캐릭터 RPLA를 구축하기 위해서는 해당 캐릭터에 대한 풍부하고 정확한 데이터가 필수적입니다. 이 데이터는 캐릭터의 정체성, 배경, 관계와 같은 기본 정보와 함께, 캐릭터의 고유한 특성을 모델이 학습하도록 돕습니다. 결국, 이 정보들이 모델이 요청 시 해당 캐릭터를 올바르게 회상하고 재현할 수 있는 기반이 됩니다.
캐릭터 데이터를 두 가지 주요 유형으로 구분합니다.
설명(Description) 데이터: 캐릭터의 이름, 소속, 정체성, 배경 등 정적인 특성을 직접 서술한 정보로, 모델이 캐릭터의 기본적인 특성을 기억하고 재현하는 데 도움을 줍니다.
데모(Demonstration) 데이터: 캐릭터의 언어 스타일, 인지 및 행동 패턴 등 동적인 특성을 대화나 상황 시연을 통해 보여주는 정보입니다.
두 데이터 유형은 상호 보완적으로 작용하여, 모델이 캐릭터의 생동감 있고 일관된 표현을 생성할 수 있도록 지원합니다.
캐릭터 데이터의 한계와 출처
사용 가능한 캐릭터 데이터는 현재 제한적이며, 주로 소수의 잘 알려진 캐릭터에 국한됩니다.
설명 데이터는 주로 신뢰할 수 있는 백과사전이나 원본 작품에서 수집되며, 수작업 또는 최신 LLM을 활용해 처리됩니다.
데모 데이터 생성 방법
경험 추출(Experience Extraction):
원본 스크립트나 대본에서 캐릭터의 대화 및 장면을 직접 추출합니다.
추출된 데이터는 캐릭터의 특성을 충실하게 담지만, 배경 지식이 부족해 실제 RPLA 학습에 한계가 있을 수 있습니다.
대화 합성(Dialogue Synthesis):
최신 LLM을 활용해 캐릭터 대화를 생성 및 보강합니다.
문헌, 일반 작업 지시, 성격 테스트 등 다양한 주제로 합성하며, 인-컨텍스트 러닝이나 직접 역할 놀이를 통해 데이터를 생산합니다.
단, 생성된 대화의 품질은 ‘teacher’ LLM의 한계로 인해 추가적인 필터링이 필요할 수 있습니다.
인간 주석(Human Annotation):
실제 인력이 직접 캐릭터 역할 놀이를 수행하여 대화 데이터를 수집합니다.
높은 데이터 품질을 보장하지만, 비용과 시간이 많이 소요됩니다.
이를 통해 기존 캐릭터뿐 아니라, 새로운 원본 캐릭터 데이터도 확보할 수 있습니다.
상호작용 데이터 및 시간적 역할 재현
RPLA와 사용자 간의 상호작용을 통해 추가적인 대화 데이터가 지속적으로 생성되며, 이는 기존 캐릭터 데이터를 보완합니다.
이 상호작용 데이터는 캐릭터 페르소나가 사용자 개별 선호에 맞춰 점진적으로 변화하도록 돕습니다.
또한, 특정 시점의 역할 놀이(예: 어린 시절의 해리 포터)를 요구하는 응용 사례는 캐릭터 지식의 시점별 제한이라는 추가적인 도전 과제를 제시합니다.
5.3 Contruction of Character RPLAs
LLM에 캐릭터 데이터를 주입하여 캐릭터 RPLA를 구축하는 과정을 설명합니다. LLM은 이미 인스트럭션 팔로잉과 캐릭터 이해 능력을 갖추고 있으므로, 제공된 데이터를 바탕으로 특정 캐릭터 역할을 수행할 수 있게 됩니다.
Parametric Training 접근법
Parametric Training 방법은 사전 학습(Pre-training)과 지도학습(Supervised Fine-Tuning)을 통해, 대규모 문헌과 백과사전 등에서 캐릭터 관련 지식을 학습시킵니다. 이를 통해 LLM은 Hermione Granger나 Socrates와 같은 기존 캐릭터의 역할을 자연스럽게 수행할 수 있도록 준비됩니다.
Nonparametric Prompting 접근법 및 메모리 모듈
Nonparametric Prompting은 프롬프트 내에 캐릭터 데이터를 직접 포함하여 LLM이 해당 캐릭터로 즉각 전환하도록 유도합니다. 다만, 캐릭터 데이터의 양이 많고 지속적인 상호작용 데이터가 누적됨에 따라, 컨텍스트 한계를 극복하기 위해 외부 메모리 모듈을 도입하는 보완적 접근이 필요합니다.
5.4 Evaluation of Character RPLAs
캐릭터 RPLA 평가에서는 모델의 역할 수행 능력(캐릭터 독립적 기능)과 특정 캐릭터의 충실도(언어 스타일, 지식, 성격, 사고 과정)라는 두 축으로 나누어 평가합니다.
Character-independent Capabilities
이 부분은 모델이 역할 놀이 작업 자체를 얼마나 잘 수행하는지 평가합니다. 평가 요소로는 대화 참여, 몰입감, 유창한 언어 생성, 감정 이해, 문제 해결 능력 등이 있으며, 다양한 상호작용 수준에 따라 기본 역할 수행 능력부터 인간에 가까운 ‘인류 모방’ 능력까지 측정합니다.
Role-playing Engagement
RPLA가 역할 놀이 상황에서 얼마나 적극적으로 참여하며 몰입하는지를 평가합니다. 에이전트는 대화 형식의 응답을 생성하고, 대화 전반에 걸쳐 일관된 인격과 역할을 유지해야 합니다. 비인격적인 표현(예: “나는 AI 모델입니다”)을 피하고, 대화의 흐름에 자연스럽게 녹아들어야 한다는 점을 강조합니다.
High-quality Conversations
RPLA가 자연스럽고 유창한 대화를 생성하는 능력을 평가합니다. 대화의 완전성, 정보 전달의 명확성, 그리고 유창한 문장 구성이 주요 평가 요소로 언급됩니다. 또한, 윤리적 기준 준수를 통해 부적절하거나 해로운 콘텐츠 생성이 방지되어야 함을 강조합니다.
Anthropomorphic Capabilities
RPLA가 인간과 유사한 인지, 감정, 사회적 지능을 얼마나 효과적으로 모방하는지를 평가합니다. 구체적으로, 대화의 매력도, 타인의 심리를 이해하는 능력(Theory of Mind), 공감 능력, 감성 지능, 그리고 목표 지향적 사회 기술 등 다양한 차원의 인간적 특성이 반영되어야 함을 설명합니다.
Character Fidelity
특정 캐릭터를 재현하는 데 있어, RPLA가 얼마나 그 캐릭터의 언어 스타일, 배경 지식, 성격 및 사고 과정을 정확하게 반영하는지를 평가합니다. 이 과정에서는 캐릭터 할루시네이션(모델이 캐릭터의 범위를 넘어선 정보를 생성하는 문제)도 함께 고려됩니다.
Linguistic Style
RPLA가 해당 캐릭터의 고유한 언어적 스타일과 어조를 얼마나 충실히 모방하는지를 평가합니다. 캐릭터의 표현 방식, 어휘 사용, 문체 등이 인-컨텍스트 러닝을 통해 재현되어야 하며, 이를 통해 캐릭터의 정체성이 자연스럽게 전달되는지 확인합니다.
Knowledge
모델이 해당 캐릭터가 보유해야 하는 배경 지식과 정체성 정보를 정확히 기억하고 재현하는 능력을 중점적으로 다룹니다. 캐릭터의 이름, 소속, 관계, 경험 등 핵심 정보를 올바르게 반영하며, 불필요하게 캐릭터 범위를 넘어선 정보를 생성하는 ‘캐릭터 할루시네이션’을 방지하는 것이 중요하다고 설명합니다.
Personality and Thinking Process
RPLA가 캐릭터의 내면적 성격과 사고 과정을 얼마나 잘 모방하는지를 평가합니다. 캐릭터의 동기, 결정 과정, 그리고 심리적 특성을 재현함으로써, 단순한 언어 스타일을 넘어 진정한 ‘캐릭터의 내면’을 표현하는지에 초점을 맞춥니다. 이를 위해 심리 평가 도구 등을 활용해 정밀하게 분석할 수 있음을 언급합니다.
Evaluation methods
평가 방법으로는 자동 평가(ground truth 기반 및 비기반), 다지선다형 문제, 그리고 전문가나 인간 평가자에 의한 인적 평가가 사용됩니다. 이러한 복합 평가 방식을 통해, 캐릭터 RPLA의 역할 수행과 충실도를 종합적으로 검증합니다.
Automatic Evaluation with Ground Truth
정답(ground truth) 데이터가 있을 때, 자동 평가 기법을 활용하여 RPLA의 응답과 기준 답변 간의 유사도를 측정하는 방법을 설명합니다. 초기에는 Rouge-L 같은 전통적 유사도 지표가 사용되었으나, 최근에는 GPT-4와 같은 첨단 LLM을 평가자로 활용하여, 주어진 기준(대개 고급 LLM이 생성한 정답)을 바탕으로 응답 점수나 우수 답변을 산출하는 방식이 주류를 이루고 있음을 언급합니다.
Automatic Evaluation without Ground Truth
정답 데이터가 부족한 상황에서, 평가 LLM이 캐릭터 프로필 등의 정보를 참고하여 RPLA 응답을 평가하는 방법에 대해 다룹니다. 이 방식은 캐릭터 독립적 능력이나 언어 스타일 평가에 효과적이지만, 캐릭터 고유의 지식과 사고 과정을 평가하는 데는 한계가 있어, 익숙하지 않은 캐릭터에 대해서는 부정확한 판단을 내릴 위험이 있음을 지적합니다.
Multi-choice Questions
객관식 문제를 활용한 평가 방식을 소개합니다. RPLA가 미리 정해진 선택지 중에서 답을 선택하도록 함으로써, 응답의 출력 공간을 축소하고 평가를 단순화할 수 있습니다. 특히, 캐릭터의 사고 과정이나 행동 예측 등에서 정답과 다소 차이가 있더라도 합리적인 응답을 평가할 수 있는 장점이 강조됩니다.
Human Evaluation
인간 평가자의 직접 평가 방식을 설명합니다. 인간 평가자는 RPLA의 응답을 정밀하게 분석할 수 있으나, 시간과 비용이 많이 들고 재현성이 낮은 단점이 있습니다. 또한, 캐릭터에 대해 깊은 이해를 가진 평가자를 확보하기 어렵다는 점이 언급되며, 일부 연구에서는 자동 평가와 인간 평가를 결합하여 평가 LLM을 미세 조정하는 시도도 진행되고 있음을 소개합니다.
6. Individualized Persona(lization)
6.1 Definition
개별화 페르소나는 사용자의 고유한 특성, 경험, 선호 등을 반영하여 LLM 기반 에이전트를 맞춤형으로 만드는 과정을 의미합니다. 이를 통해 디지털 클론이나 개인 비서처럼, 사용자의 개별 요구에 최적화된 서비스를 제공할 수 있습니다.
개인화된 RPLA의 응용은 주로 세 가지 영역으로 구분됩니다.
대화: 사용자의 스타일과 취향에 맞춘 상호작용 지원
추천: 개인의 선호를 반영한 맞춤형 추천 기능 제공
과제 해결: 복잡한 작업을 자율적으로 수행할 수 있는 기능 구현
개인화 페르소나 구축은 두 가지 주요 단계로 이루어집니다.
페르소나 데이터 수집: 사용자 프로필, 대화 기록, 도메인 지식 등 다양한 형태의 데이터를 모읍니다.
페르소나 모델링: 수집된 방대한 데이터 내에서 노이즈와 희소성을 극복하며, 사용자의 고유 특성을 효과적으로 내재화하는 모델을 설계합니다.
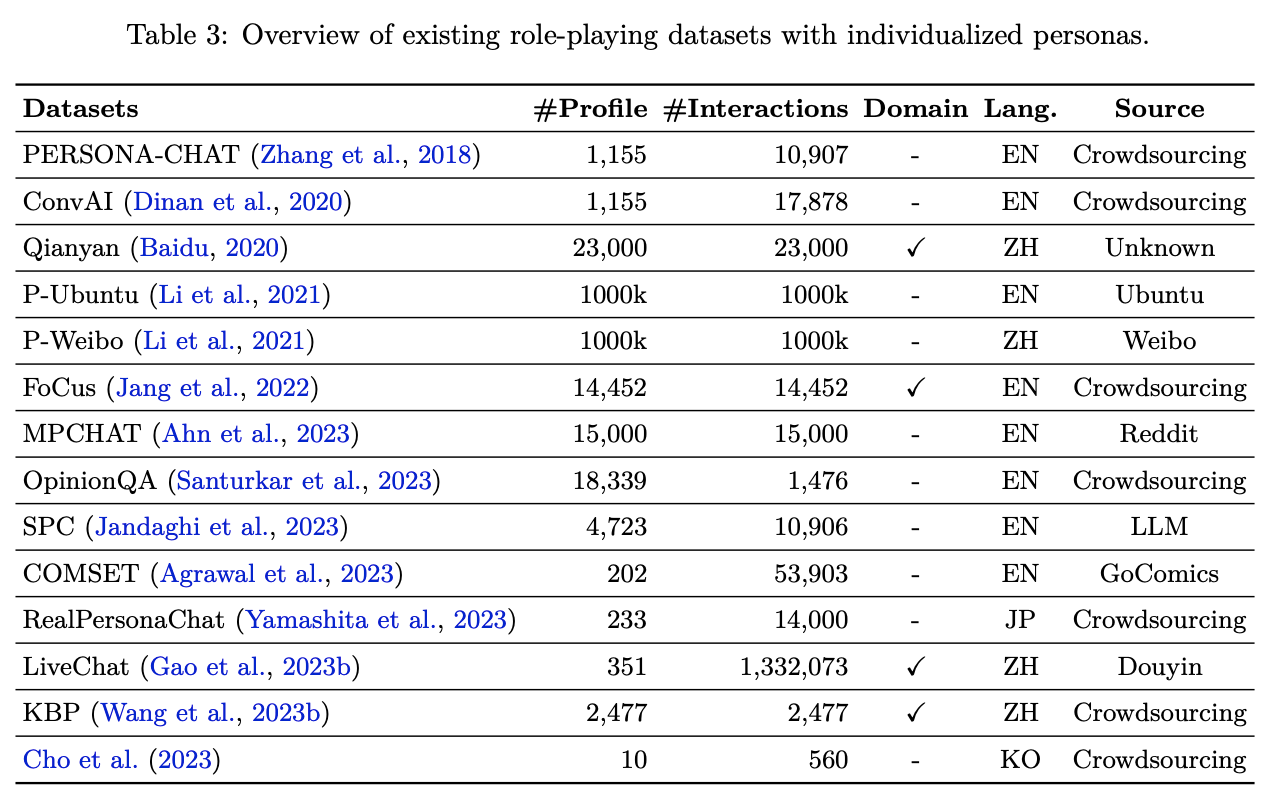
6.2 Data Collection of Individualized Persona
개인화 페르소나를 구축하기 위해 수집해야 하는 데이터는 주로 세 가지 유형으로 구성됩니다.
프로필 데이터: 사용자의 나이, 성별, 직업 등 기본 정보를 포함합니다.
상호작용 데이터: 사용자의 대화 기록 및 행동 패턴을 캡처합니다.
도메인 지식: 사용자의 관심사나 특정 분야 관련 전문 정보를 반영합니다.
수집된 다양한 데이터는 양이 많고 희소하며 노이즈가 포함될 가능성이 있으므로, 이를 효과적으로 전처리하고 통합하는 과정이 필수적입니다.
6.3 Modeling Individualized Persona
개별화 페르소나 모델링의 목표와 필요성을 소개하며, 두 가지 주요 학습 전략인 offline learning(사전 배치 학습)과 online learning(실시간 업데이트)이 상호 보완적으로 활용된다는 전체 개요를 제시합니다.
Offline Learning
오프라인 학습은 사용자 프로필, 대화 기록, 도메인 지식 등 과거에 수집된 정적 데이터를 기반으로 모델을 초기 학습시키는 방법을 설명합니다. 데이터 전처리 및 통합 과정을 통해 노이즈와 희소성을 극복하고, 사용자의 고유 특성을 안정적으로 내재화하는 모델을 구축합니다. 초기 페르소나 표현의 기초를 마련하여, 이후 실시간 업데이트의 기반이 됩니다.
Online Learning
온라인 학습은 실제 사용자와의 상호작용을 통해 지속적으로 모델을 업데이트하는 방법을 다룹니다. 사용자 피드백과 최신 상호작용 데이터를 반영하여, 개별 페르소나가 시간에 따라 변화하는 사용자의 특성을 실시간으로 포착합니다 . 모델의 유연성을 높여, 최신 사용자 정보에 기반한 맞춤 응답을 제공하도록 보완합니다.
오프라인 학습으로 구축된 초기 페르소나와 온라인 학습으로 반영되는 최신 정보 사이의 균형 유지가 필요함을 강조합니다.
6.4 Evaluation for LLMs and Individualized Persona
평가 기준은 LLM이 사용자 개별 특성을 얼마나 효과적으로 반영하는지, 그리고 다양한 응용 상황에서 맞춤형 응답을 제공하는지에 중점을 둡니다.
평가 항목은 대화, 추천, 과제 해결 등 서로 다른 사용 사례에 따라 구분되며, 각 범주별로 세부 평가 기준이 존재함을 설명합니다.
Converstaion
사용자의 대화 스타일, 문체, 그리고 상황에 맞는 응답 생성 능력 등, 대화의 몰입도와 개인화 정도가 주요 평가 요소로 다뤄집니다.
Recommendation
사용자 선호와 과거 상호작용을 반영해 관련성 높은 추천을 생성하는지, 그리고 추천 과정이 다중 턴 대화 속에서 자연스럽게 이루어지는지를 중점적으로 살펴봅니다.
Task Solving
사용자 개별 데이터를 효과적으로 활용하여 도메인별 문제 해결, 계획 수립 등 고차원적인 작업을 자율적으로 처리할 수 있는지, 그리고 그 결과물이 얼마나 실용적인지를 검토합니다.
7. Risks Beneath RPLA Applications
7.1 Toxicity
Inherent Toxicity in LLMs
LLM은 대규모 텍스트 데이터에서 학습하면서, 데이터에 내재한 부정적 언어 패턴, 사회적 편향, 고정관념 등을 함께 학습합니다. 이로 인해 모델은 기본적으로 독성(toxic) 언어를 생성할 가능성이 있으며, 이는 의도치 않게 해로운 표현이나 공격적인 언어로 이어질 수 있습니다.
The RPLAs Conundrum
역할 놀이 에이전트(RPLA)는 특정 페르소나를 시뮬레이션하기 위해 고의적으로 다양한 인격적 특성을 구현합니다. 그러나 이러한 페르소나 구현 과정에서, 독성 표현이나 부적절한 행동이 더욱 부각될 수 있는 딜레마(Conundrum)가 발생합니다. 즉, 역할 재현의 사실성과 몰입감을 높이려 할수록, 원래 내재되어 있던 독성 문제도 함께 노출될 위험이 커집니다.
Strategies for Balancing Safety and Performance
독성 문제를 완화하면서도 에이전트의 역할 수행 능력을 유지하기 위한 다양한 전략들이 논의됩니다. 여기에는 강화학습(예: 인간 피드백 강화 학습: RLHF), 프롬프트 설계의 정교화, 안전 필터 및 후처리 기법 등이 포함되어, 독성이 낮은 동시에 성능 좋은 출력을 도출하려는 노력이 강조됩니다.
7.2 Bias
Bias Manifestation in Role-Playing Scenarios
역할 놀이 상황에서는 LLM이 학습 데이터에 존재하는 사회적, 문화적 편향을 그대로 재현하는 경우가 많습니다. 특정 인물이나 집단에 대해 고정관념적인 서술이나 부정확한 표현이 나타날 수 있으며, 이는 사용자 경험에 부정적 영향을 미칩니다.
Causes of Bias in RPLAs
편향의 주요 원인은 불균형한 학습 데이터, 모델 설계 상의 한계, 그리고 사회 전반에 존재하는 선입견 등입니다. 특히, 대규모 웹 크롤링 데이터는 다양한 편향을 포함하고 있어, 이를 그대로 학습하면 RPLA가 편향된 페르소나를 생성할 수 있습니다.
Strategies for Mitigating Bias
데이터 다양화 및 반편향 데이터셋 구축, 알고리즘적 수정, 프롬프트 설계 개선 등 여러 전략을 통해 편향 문제를 완화하는 방안이 제시됩니다. 또한, 평가 과정에서 편향을 감지하고 수정하는 후처리 단계도 중요한 역할을 하며, 지속적인 모니터링과 업데이트가 필요합니다.
Persona Construction Bias
페르소나를 구성하는 과정 자체에서 선택되는 특성, 서술 방식, 혹은 데이터의 출처가 편향을 강화할 수 있습니다. 따라서, 페르소나 설계 시에도 다양한 관점과 균형 잡힌 정보를 반영하여, 특정 집단이나 인물에 대한 왜곡된 표현을 최소화하는 노력이 요구됩니다.
7.3 Hallucination
Hallucination in RPLAs
LLM은 때때로 학습 데이터에 근거하지 않은 정보를 생성하는 ‘할루시네이션’ 문제를 보입니다. 특히, 역할 놀이 상황에서는 캐릭터의 배경이나 특성을 과도하게 일반화하거나 부정확한 세부 정보를 추가하는 경우가 발생합니다.
Mitigating Hallucinations in RPLAs
할루시네이션 문제를 줄이기 위해, 외부 지식 검색(Retrieval-augmented Generation) 기법, 데이터 보강, 그리고 미세 조정(fine-tuning) 기법이 적용됩니다. 또한, 생성된 텍스트의 사실성을 검증하는 자동 평가 및 인간 평가 절차를 통해, 할루시네이션 발생 빈도를 낮추고 보다 신뢰성 있는 출력을 도출하려는 노력이 강조됩니다.
7.4 Privacy Violations
Privacy Challenges in LLMs
LLM은 대규모 데이터 학습 과정에서 민감한 정보나 개인 정보를 무심코 학습할 가능성이 있습니다. 이로 인해, 생성된 텍스트에 원치 않는 개인 정보가 포함되거나, 데이터 유출과 관련된 위험이 발생할 수 있습니다.
Hidden Danger of Privacy Violations in RPLAs
RPLA는 개별 사용자 데이터를 활용해 개인화된 서비스를 제공하기 때문에, 더욱 은밀하게 개인정보가 노출될 위험이 있습니다. 사용자의 대화 기록이나 행동 패턴이 부적절하게 처리되면, 프라이버시 침해 사례가 발생할 수 있음을 경고합니다.
Strategies for Enhancing Privacy
개인정보 보호를 위해 데이터 익명화, 안전한 저장 및 접근 제어, 그리고 차등 개인정보 보호(Differential Privacy) 기법 등이 제안됩니다. 또한, 모델이 민감 정보를 학습하지 않도록 하는 사전 필터링 및 후처리 단계도 중요하며, 실시간 모니터링 체계를 도입하는 방안도 고려됩니다.
7.5 Technical Challenges in Real-world Deployment
Lack of Social Intelligence and Theory of Mind
실제 사회적 상호작용에서 LLM은 인간과 같은 사회적 지능이나 타인의 심리를 예측하는 능력이 부족합니다. 이로 인해, 복잡한 사회적 맥락이나 미묘한 감정 표현, 상호작용의 뉘앙스를 정확하게 파악하기 어려워집니다.
Long-context Challenges
긴 대화나 복잡한 시나리오에서 컨텍스트를 효과적으로 유지하는 데 한계가 있습니다. LLM의 고정된 컨텍스트 윈도우로 인해, 장시간 상호작용 시 중요한 정보가 누락되거나 일관성이 떨어지는 문제가 발생할 수 있습니다.
Knowledge Gaps
LLM은 최신 정보나 특정 도메인에 대한 전문 지식에서 간극이 존재할 수 있으며, 이로 인해 역할 놀이 과정에서 부정확하거나 불완전한 정보를 제공할 위험이 있습니다. 특히, 시시각각 변화하는 실시간 정보나 최신 트렌드를 반영하는 데 어려움이 있음이 강조됩니다.
7.6 Anthropomorphism
Social Isolation
인간과 매우 유사한 에이전트가 실제 인간과의 상호작용을 대체하게 되면, 사회적 고립 현상이 촉발될 우려가 있습니다. 특히, 개인화된 RPLA가 인간 관계의 대체재로 인식되면, 인간 상호작용의 질이 저하될 수 있습니다.
Manipulation of Public Opinion
RPLA가 인간처럼 보이고 행동함으로써, 공공 여론이나 사회적 이슈에 영향을 미칠 수 있는 잠재적 위험이 있습니다. 특히, 정치적 또는 사회적 맥락에서 인위적으로 설계된 페르소나를 이용해 잘못된 정보 확산이나 여론 조작이 시도될 수 있음을 경계합니다.
8. Closing Remarks
연구진은 RPLA가 다양한 페르소나 구현과 개인화 기술을 통해 사용자 맞춤형 상호작용을 제공할 수 있는 점을 강조하면서도, 안전성, 편향, 할루시네이션 등 해결해야 할 문제들이 여전히 남아 있음을 지적합니다. 또한, 이 장은 후속 연구를 위한 방향성을 제시하며, 앞으로의 발전 가능성과 응용 분야에 대해 논의합니다.
Future Directions on RPLA Systems
RPLA 시스템이 미래에 나아가야 할 연구 방향과 도전 과제들을 제시합니다. 연구진은 현재의 한계들을 극복하고, 보다 정교하고 유연한 역할 놀이 에이전트를 개발하기 위해 다양한 측면에서 개선이 필요하다고 설명합니다. 특히, 의사결정 지원, 개인 맞춤형 서비스, 그리고 자율적인 사회 시뮬레이션과 같은 영역에서 새로운 연구 기회가 열릴 것임을 강조하며, 각 방향에 대한 구체적인 연구 아이디어를 제안합니다.
Causal Data Analysis for Decision-making:
RPLA가 사용자와의 상호작용에서 발생하는 데이터의 인과 관계를 분석하는 것의 중요성을 다룹니다. 단순한 상관관계에 머무르지 않고, 어떤 요인이 결과에 직접적인 영향을 미치는지 파악함으로써, 에이전트가 보다 정확하고 신뢰성 있는 결정을 내릴 수 있도록 돕는 방법을 제시합니다. 이러한 인과 분석은 모델이 불필요한 노이즈를 제거하고, 핵심 변수에 집중하여 의사결정 과정을 개선하는 데 중요한 역할을 할 것으로 기대됩니다.
Improved Decision-making:
RPLA의 의사결정 능력을 한층 더 강화하기 위한 전략을 설명합니다. 여기서는 고급 추론 알고리즘과 실시간 피드백 메커니즘을 도입하여, 복잡한 상황에서도 논리적이고 일관된 결정을 내릴 수 있도록 하는 방안을 논의합니다. 즉, 단순히 인간의 행동을 모방하는 것을 넘어, 다양한 변수와 불확실성을 고려한 체계적인 의사결정 프로세스를 구축하는 것이 목표입니다.
RPLA as Personal Assistants for Personal Decision-making:
개인화된 RPLA가 사용자의 일상적인 의사결정을 지원하는 개인 비서로 발전할 가능성을 제시합니다. 에이전트가 사용자의 프로필, 대화 기록, 그리고 선호 데이터를 실시간으로 반영함으로써, 개인별로 맞춤형 조언과 결정을 제공할 수 있는 방향을 모색합니다. 이로 인해, 사용자는 보다 효율적이고, 개인화된 방식으로 일상 문제를 해결할 수 있으며, RPLA는 단순한 역할 놀이를 넘어서 실질적인 개인 비서로서의 역할을 수행할 수 있게 됩니다.
Social Simulation through Autonomous Role-Playing:
RPLA가 자율적으로 다수의 에이전트와 상호작용하며, 실제 사회적 상황을 모사하는 사회 시뮬레이션 시스템으로 발전할 수 있는 가능성을 논의합니다. 이를 통해, 복잡한 집단 의사결정, 사회적 규범 및 역학을 재현하는 동시에, 인간 사회의 다양한 행동 패턴에 대한 통찰을 제공할 수 있는 연구 분야로 확장될 수 있습니다. 이러한 자율적 사회 시뮬레이션은 RPLA가 단순히 개별 사용자와의 상호작용을 넘어, 집단 내 협업이나 경쟁 상황에서도 유용하게 활용될 수 있음을 시사합니다.
의사 결정의 피드백 주기가 수 번 이상 순환해야 한다. 일을 하면서 스스로가 개입한 엔지니어링 선택들이 좋은 결과로 이어졌는지 그렇지 않은지에 대해 알아야 한다. 어떤 엔지니어링 선택들은 결과를 보기까지 수개월에서 수년이 걸리므로 근속 기간이 짧다면 내 선택이 얼마나 맞고 틀렸는지에 대한 감각이 쌓이기 어렵다.
...
무조건 제품 운영을 해봐야 한다. 제품을 맨 처음부터만 만들고 계속 떠나보냈던 엔지니어는 성숙하고 오래 영속하는 소프트웨어의 운영 이슈들을 잘 알기 힘들다. 내 코드가 제품 안에서 몇 년이고 살아있을 가능성을 전제로 엔지니어링을 하지 못한다. 인터뷰어로 채용에 참여했을 때, 가장 확인하고 싶었던 인터뷰이의 경험 중 하나는 "프로덕트를 꽤 오랜 기간 운영해본 경험이 있냐는 것"이었다. 그런 경험이 없다면 코드 안에 너무 많은 암묵지를 만들어내고, 흑마법을 쉽게 사용하고, 은연중에 더 위험한 코드를 작성하게 될 가능성이 높아지리라는 우려가 있다.
오랫동안 하나의 제품을 운영해보면서 기술적 판단에 대한 결과를 확인하고 성찰하고 개선하는 시간이 필요함
Q. 후배들 중에 개그맨이나 혹은 예능인이나 이렇게 좀 다른 사람을 즐겁게 해주는 거를 업으로 삼고 싶은 사람들이게 ‘어떤 식으로 해야 남들을 좀 더 즐겁게 하고 웃길 수 있다‘라고 조언을 하시겠습니까?
A. 일단 기본적으로 인간을 사랑해야됩니다. 이게요 내가 상대를 웃겼을 때이 사람이 웃는다 말이에요. 그럼 내가 즐거워야 돼. 그 기쁨을 느끼지 못하면 하면 안 돼, 예능인들은. 내가 이렇게 이렇게 했는데 이 사람이 웃어? 어 나 즐거워. 그러니까 어떤 분들 있잖아요. 요리를 막 해서 남 주면 남이 먹었을 때 좋아하시는 분들 있어요. 그런 사람이 요리 잘해요. 그러니까 예능인이다. 내가 남한테 웃음을 주겠다. 그러면 상대방이 웃었을 때 내가 과연 기뻐하는가. 기뻐하면 그 사람은 자격이 있는 거예요.
사람은 사람을 좋아해야 인생 살기 쉽다
직업은 내가 다른 사람에게 무엇을 해줬을 때 즐거움을 얻는지를 알아내야한다
예를 들어, 개그맨의 경우 다른 사람에게 웃음을 줬을때 내가 행복하다면 지속 가능하다 요리사의 경우 다른 사람에게 요리를 해주고 남이 먹었을 때 행복감을 느낀다
나는 다른 사람에게 어떤 경험을 줄때 행복감을 느끼는가?
내가 만든 소프트웨어가 타인의 문제를 해결 해줄 때, 더 이상 내가 만든 기능이 없던 시절로 돌아갈 수 없을 정도로 편리함을 느낄 때.
혹은 요즘 드는 생각인데 내가 만든 소프트웨어로 즐거움과 재미를 느낀다면 좋을거같음
다음으로 그 일을 잘하기 위해서는 평가 대상의 신뢰를 얻고 좋은 평가를 받을 수 있도록 해야 한다

 zoomg
zoomg