
Open LLM Leaderboard - a Hugging Face Space by HuggingFaceH4
Discover amazing ML apps made by the community

I-JEPA: The first AI model based on Yann LeCun’s vision for more human-like AI
I-JEPA learns by creating an internal model of the outside world, which compares abstract representations of images (rather than comparing the pixels themselves).


Segment Anything: TorchServe로 배포하기 - code 포함
Segment Anything model을 TorchServe를 통해 배포하는 과정을 Code를 통해서 상세하게 알려드립니다. python code와 docker를 사용해 추론 환경을 만드는 과정이 포함되어 있습니다.
 유지수
유지수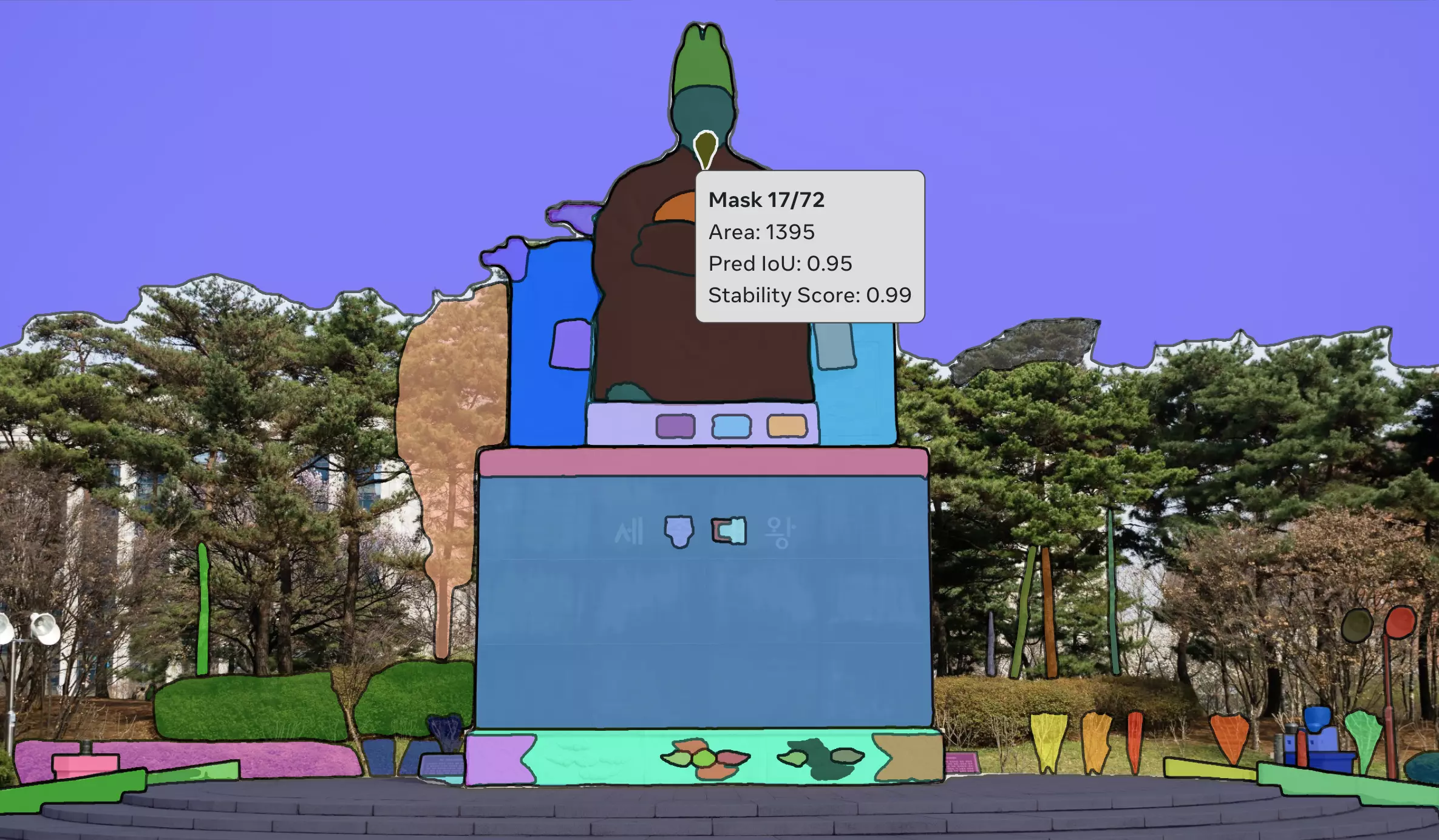
논문리뷰 Segment Anything | SAM
Segment Anything Model은 SAM은 객체 식별 성능, 클래스(=객체 카테고리) 자유도, 작거나 복잡한 객체에 대한 세분화된 분할, 실시간 처리, 쉬운 서비스 통합 및 사용 등 다양한 측면에서 이점을 갖는 모델입니다.
조수호
Comparing current and prior imaging studies in radiology AI
Today’s AI radiology solutions don’t effectively account for past imaging findings despite their routine use by radiologists. BioViL-T jointly trains text and image encoders that can ground radiology text across longitudinal images:
