
자료
[ DeepSeek-R1 ] paper review
DeepSeek-R1 Review.

[논문리뷰] DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-R1 논문 리뷰
DeepSeek의 R1-Zero 및 R1 분석 | GeekNews
ARC Prize Foundation은 AGI(인공지능 일반화)를 정의하고, 측정하며, 새로운 아이디어를 고취하는 것을 목표로 함AGI를 아직 달성하지 못했으며, 순수 LLM(대규모 언어 모델) 사전 훈련의 확장이 해결책이 아님2023-24년 동안 LLM 스타트업에 약 200억 달러가 투자된 반면, AGI 스타트업에는 약 2억 달러만 투자됨DeepSeek의
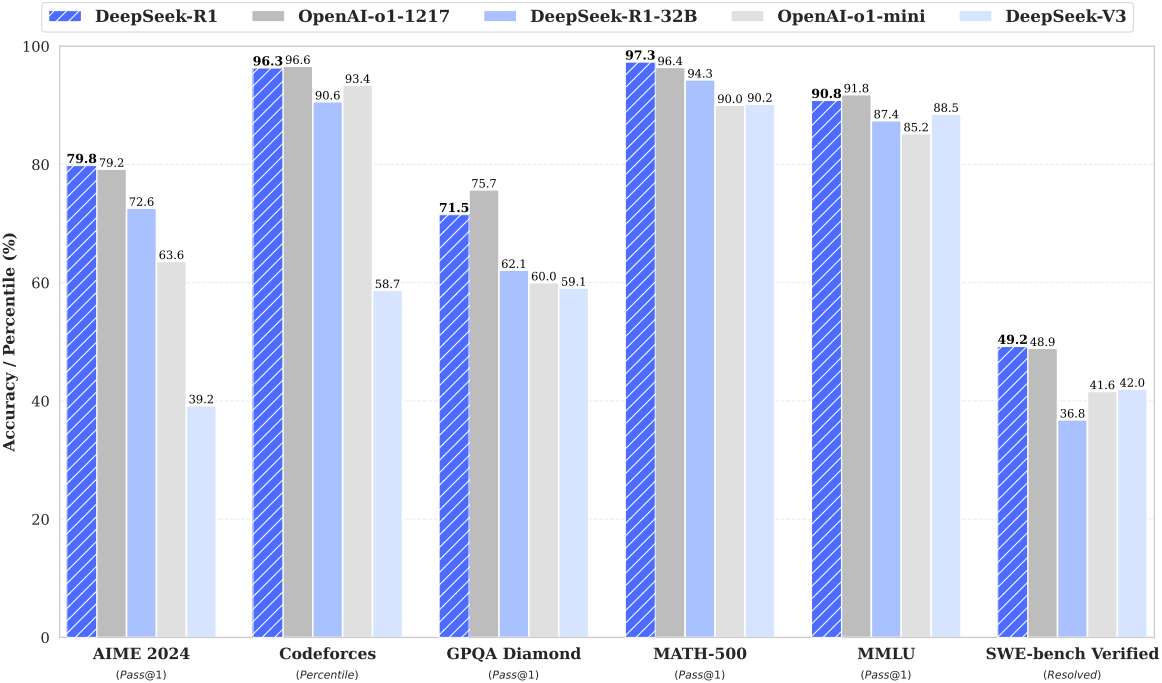
R1-Zero and R1 Results and Analysis
An analysis of Deepseek’s R1
 Mike Knoop
Mike Knoop
ARC-Prize의 R1-Zero 평가 전문 번역 - 특이점이 온다 마이너 갤러리
R1-Zero는 R1보다 더 중요합니다R1 학습 아키텍처지난주 DeepSeek은 새로운 R1-Zero와 R1 “reasoner” 시스템을 공개했는데, 이는 OpenAI의 o1 시스템과 ARC-AGI-1에서 대등하게 경
Notion – The all-in-one workspace for your notes, tasks, wikis, and databases.
A new tool that blends your everyday work apps into one. It’s the all-in-one workspace for you and your team

이승우 on LinkedIn: 한 장으로 이해하는 DeepSeek-R1 학습법
DeepSeek-R1-Zero와 DeepSeek-R1 모델의 학습 과정을 한 눈에 알아볼 수 있도록 정리된 자료 공유드립니다. <DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning>…
 이승우
이승우
DeepSeek-R1, 지도학습 기반 파인튜닝(SFT) 대신, 강화학습(RL)으로 추론 능력을 개선하여 추론 능력을 강화한 대규모 언어 모델
연구 배경 및 소개 대규모 언어 모델(LLM, Large Language Model)은 최근 몇 년간 비약적으로 발전하며 인공지능(AI) 연구에서 핵심적인 위치를 차지하고 있습니다. 특히 OpenAI, Anthropic, Google 등의 연구 기관이 개발한 최신 모델들은 언어 이해와 생성뿐만 아니라 수학, 과학, 코딩 등 다양한 논리적 추론 작업에서 탁월한 성능을 보여주고 있습니다. 하지만 기존 연구들은 대부분 사전 학습(pre-training)과 지도학습(supervised fine-tuning)을 기반으로 하고 있으며, 이는…
 9bow
9bow
LLM과 간단한 보상 시스템으로 뛰어난 성능의 시스템을 만들 수 있다
= 정확도를 평가할 수 있는 지표만 있다면, 강화학습으로 전문가 모델을 만드는건 이제 어려운 일이 아니다
* 강화학습을 위해 사용한 데이터 수는 공개되어 있지 않고, 만약 억 단위의 데이터라면 만들기 쉽지않다
+ 예전에 o1팀의 인터뷰에서 알게된 부분과 동일 (전문가 제작을 위한 보상 시스템)
OpenAI o1 팀 이야기 체리픽
Q4: 여러분 모두에게 그런 ‘아하’ 순간이 있었나요? 예를 들어, GPT-2, GPT-3, GPT-4를 훈련시켰을 때, 모델이 막 완성되어 모델과 대화를 시작하고 사람들이 ”와, 이 모델 정말 대단해”라고 말했던 첫 순간 같은 것 말입니다. 추론을 위한 모델을 훈련시킬 때, 가장 먼저 떠오르는 것은 인간이 자신의 사고 과정을 작성하고 그것을 훈련시키는 것입니다.
 zoomg
zoomg
그저 policy와 reward를 잘 설계 했을 뿐, 전문가의 사고방식을 모방하지 않음
전문가가 처해있는 상황을 잘 묘사했을 뿐
SFT는 인간과 소통을 위해 소량 사용한다
= 인간이 발전에 방해된다, 인간이 평가할 수 없는 상태가 된다